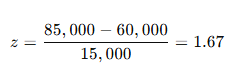A normal distribution, also known as a Gaussian distribution, is a type of probability distribution in which the values of a random variable are distributed symmetrically around the central tendency—typically the mean. In this distribution, data points are equally spread on both sides of the mean, creating a characteristic bell-shaped curve when graphed.
This curve illustrates that most values cluster around the mean, while the frequency of extreme values (either very high or very low) decreases progressively as one moves away from the center. The peak of the curve corresponds to the mean, median, and mode, which are all equal in a perfect normal distribution.
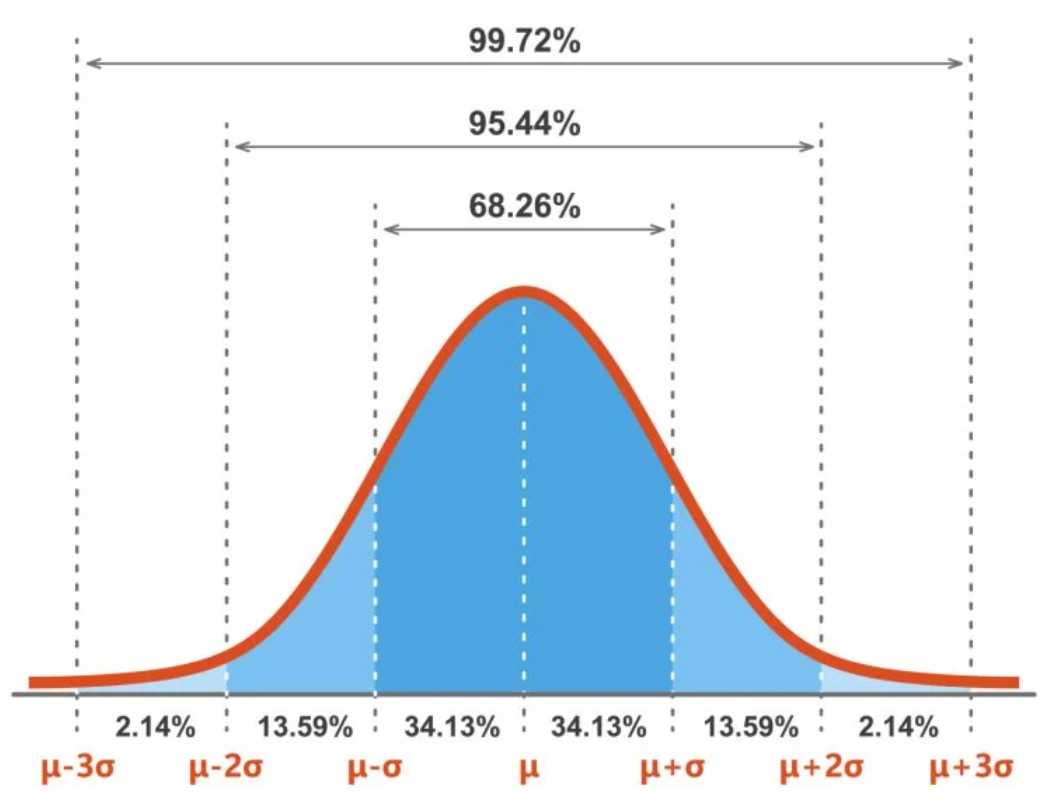
Furthermore, the empirical rule (or 68-95-99.7 rule) applies to normal distributions. According to this rule:
-
Approximately 68% of the data values fall within one standard deviation from the mean.
-
Around 95% lie within two standard deviations.
-
And about 99.7% of the data is contained within three standard deviations of the mean.
This predictable pattern makes the normal distribution a fundamental concept in statistics, widely used in natural and social sciences to model real-world phenomena.
Explanation of the Normal Distribution
A normal distribution, also known as a Gaussian distribution, represents a symmetrical probability distribution where most data points are concentrated around the mean, forming a bell-shaped curve. This distribution is defined by two fundamental parameters:
-
Mean (µ): Determines the center or location of the distribution.
-
Standard deviation (σ): Measures the spread or dispersion of data around the mean.
This probabilistic model plays a crucial role in various statistical applications, including asset return estimation, risk management, and decision-making strategies. The bell-shaped curve that characterizes the normal distribution aligns with the empirical rule (also called the 68-95-99.7 rule), which governs the spread of observations:
-
Approximately 68% of all data points lie within ±1 standard deviation from the mean.
-
Around 95% fall within ±2 standard deviations.
-
Nearly 99.7% are found within ±3 standard deviations.
The curve theoretically extends infinitely in both directions, meaning that the tails of the curve approach but never touch the horizontal axis. This indicates that extreme values are possible, although they occur with low probability.
Skewness and Kurtosis
-
Skewness measures the symmetry of the distribution.
-
A skewness of 0 indicates perfect symmetry (i.e., a true normal distribution).
-
A positive skew (skewness > 0) means the right tail is longer or fatter than the left.
-
A negative skew (skewness < 0) means the left tail is longer or fatter than the right.
-
-
Kurtosis measures the tailedness or peak sharpness of the distribution.
-
A kurtosis of 3 corresponds to a normal distribution (also called mesokurtic).
-
A kurtosis greater than 3 indicates a leptokurtic distribution (sharper peak and fatter tails).
-
A kurtosis less than 3 indicates a platykurtic distribution (flatter peak and thinner tails).
-
Key Characteristics of the Normal Distribution
-
Empirical Rule:
The distribution adheres to the 68-95-99.7 principle regarding standard deviations from the mean. -
Bell-Shaped Curve:
Most values are concentrated around the center, with fewer observations as one moves toward the tails. -
Defined by Mean and Standard Deviation:
The shape and spread of the distribution are entirely determined by these two parameters. -
Equality of Central Tendencies:
The mean, median, and mode are all equal in a perfectly normal distribution. -
Perfect Symmetry:
The curve is symmetrical about the mean. This implies that half of the data lies to the left of the mean and the other half to the right. -
Zero Skewness and Standard Kurtosis:
-
Skewness = 0 → Perfect symmetry.
-
Kurtosis = 3 → Normal level of peak and tail thickness.
-
Conditions for a Normal Distribution
To determine whether a dataset follows a normal distribution, the following conditions should be satisfied:
-
The histogram or graph of the data should show a symmetrical bell-shaped curve.
-
Mean = Median = Mode.
-
The mean of the distribution is 0 (for a standardized normal distribution).
-
The standard deviation is 1 (again, for the standardized version).
-
Skewness is 0.
-
Kurtosis is 3.
Applications and Relevance
The Gaussian (normal) distribution is one of the most widely used probability distributions in both theoretical and applied statistics. It models numerous real-world phenomena due to its mathematical properties and interpretability. Its applications span across disciplines, including but not limited to:
-
Economics and finance (e.g., modeling asset returns)
-
Investment analysis and risk assessment
-
Psychology and social sciences
-
Natural sciences
-
Healthcare and medicine
-
Business intelligence and market research
Its widespread usage is largely attributed to the Central Limit Theorem, which states that the distribution of sample means approaches a normal distribution as the sample size increases, regardless of the original data distribution.
Normal Distribution Formula
The probability density function (PDF) of a normally distributed random variable XX is given by the following formula:
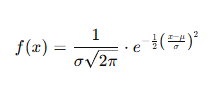
Where:
-
x = Random variable
-
μ = Mean of the distribution
-
σ = Standard deviation of the distribution (must be > 0)
-
π≈ 3.14159 (mathematical constant)
-
e ≈ 2.71828 (base of the natural logarithm)
-
The domain of x, μ, and σa is:
-
−∞<x<∞
-
−∞<μ<∞
-
σ>0
-
This function describes the likelihood of a given value xx occurring in a normal distribution. The curve peaks at x=μx = \mu, and its shape is governed by the standard deviation σ. The wider the standard deviation, the flatter the curve; the smaller the standard deviation, the steeper and narrower the curve.
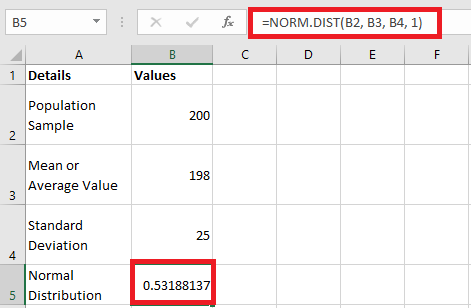
Z-Score Transformation (Standardization)
When comparing different datasets or conducting inferential statistics, it is often necessary to standardize values from different normal distributions. This is done using the Z-score transformation, which converts a raw score into a standardized score indicating how many standard deviations the value is from the mean.
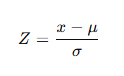
Where:
-
Z= Standardized score (Z-score)
-
x = Original value or raw score
-
μ= Mean of the distribution
-
σ= Standard deviation of the distribution
The Z-score allows us to compare scores across different normal distributions and to determine the relative position of a value within a distribution.
Standard Normal Distribution Table (Z-Table)
The Z-table, or standard normal table, is used to find the cumulative probability associated with a given Z-score in the standard normal distribution (where μ=0 and σ=1). It tells us the probability that a random variable XX is less than or equal to a given Z value.
Example:
If Z=1.96, the Z-table shows that approximately 97.5% of the data lies below that value in a standard normal distribution.
The steps to use the Z-table are:
-
Standardize the raw value using the Z-score formula.
-
Locate the Z value in the Z-table.
-
Interpret the cumulative probability, often expressed as a percentage.
This process is essential in hypothesis testing, confidence interval estimation, and many other applications in inferential statistics.
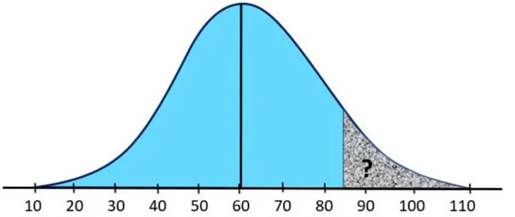
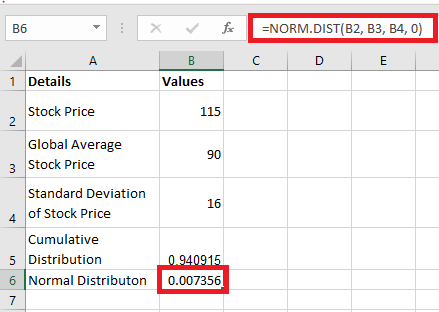
Example 1
Suppose a company has 10,000 employees and several salary structures based on specific job functions. Salaries are generally distributed with a mean of μ = $60,000 and a population standard deviation σ = $15,000. What is the probability that a randomly selected employee earns less than $45,000 per year?
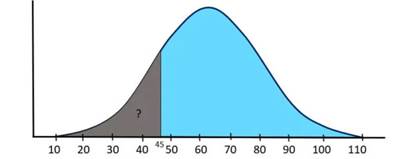
Solution:
As shown in the figure above, we need to determine the area under the normal curve from $45,000 to the left tail in order to answer this question. Additionally, we must use the z-table value to obtain the correct answer.
First, we need to convert the given mean and standard deviation into a standard normal distribution with a mean (μ) = 0 and a standard deviation (σ) = 1 by using the transformation formula.
After the conversion, we consult the z-table to find the corresponding value, which will give us the correct result.
Given:
-
Mean (μ) = $60,000
-
Standard deviation (σ) = $15,000
-
Random variable (x) = $45,000
Transformation (z):
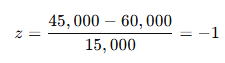
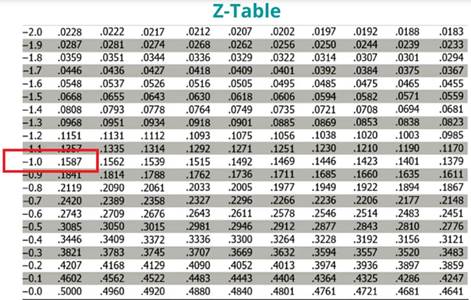
The value corresponding to z = -1 in the z-table is 0.1587, representing the area under the curve from $45,000 to the left. This indicates that when an employee is randomly selected, the probability of earning less than $45,000 per year is 15.87%.
It is important to note that we converted the z-score value 0.1587 into a percentage by multiplying it by 100, resulting in 15.87%.