Votre panier est actuellement vide !
Étiquette : function
How to use the BINOM.INV() function in Excel
This function returns the minimum number of successes (k) in a binomial distribution where the cumulative probability is ≥ a specified threshold (alpha). It is the inverse of BINOM.DIST().
Syntax
BINOM.INV(trials; probability_s; alpha)
Key Use Case:
- Quality Control: Determine the maximum allowable defective items in a batch before rejecting it.
- Decision-Making: Find critical thresholds for pass/fail scenarios (e.g., survey results, manufacturing tolerances).
Arguments
Argument Required? Description trials Yes Total number of independent trials (e.g., 100 surveys). probability_s Yes Probability of success per trial (e.g., 0.5 for 50%). alpha Yes Target cumulative probability threshold (e.g., 0.95 for 95% confidence). Background
- Inverse Binomial Distribution:
- Solves for k in:
P(X≤k)≥αP(X≤k)≥α
-
- Where:
- P = Cumulative binomial probability.
- k = Maximum successes allowed before exceeding the threshold.
- Where:
- Assumptions:
- Trials are independent (e.g., coin flips, quality checks).
- Only two outcomes per trial (success/failure).
- Relation to BINOM.DIST():
- If BINOM.DIST(k, n, p, TRUE) = alpha, then BINOM.INV(n, p, alpha) = k.
Example: Vacation Survey
Scenario:
- You ask 100 people for directions, each with a 50% chance (p = 0.5) of answering « yes. »
- Question: What is the maximum number of « yes » responses (k) where the cumulative probability ≤ 0.1% (alpha = 0.001)?
Formula:
BINOM.INV(100, 0.5, 0.001)
Result: 35 (see Figure below).
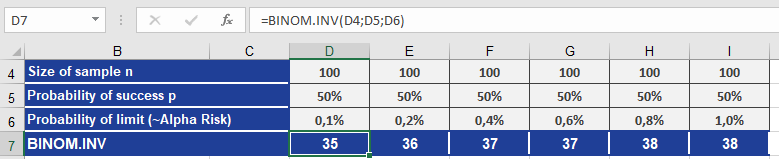
Interpretation:
- There is a 0.1% chance that 35 or fewer people would say « yes » by random chance.
- If you observe >35 « yes » answers, the result is statistically significant (exceeds the threshold).
Key Notes
- Quality Control Application:
- If a batch of 1,000 parts has a 2% defect rate (p = 0.02), use BINOM.INV() to find the maximum defects allowed before rejecting the batch (e.g., for alpha = 0.95).
- Threshold Logic:
- Lower alpha = Stricter criteria (fewer allowed successes).
- Higher alpha = More lenient criteria (more allowed successes).
- Limitations:
- For large trials (e.g., >1,000), consider approximations like the Normal distribution.
How to use the BINOM.DIST() function in Excel
This function calculates probabilities for a binomial distribution, which models scenarios with:
- A fixed number of trials (trials).
- Only two outcomes per trial: success or failure.
- Independent trials with a constant success probability (probability_s).
Syntax
BINOM.DIST(number_s; trials; probability_s; cumulative)
Example Use Case:
- Calculating the probability that 50 out of 100 people support a smoking ban, given each has a 60% chance of supporting it.
Arguments
Argument Required? Description number_s Yes Number of successful trials (e.g., 50 « yes » responses). trials Yes Total number of trials (e.g., 100 surveys). probability_s Yes Probability of success per trial (e.g., 0.6 for 60%). cumulative Yes TRUE = Cumulative probability (≤ number_s successes).
FALSE = Exact probability (exactly number_s successes).Background
- Binomial Distribution Basics:
- Models counts of successes in n independent Bernoulli trials (e.g., coin flips, survey responses).
- Probability Mass Function (PMF):
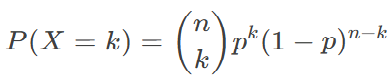
-
-
- (nk)(kn) = Combination of n trials with k successes (COMBIN(n, k) in Excel).
- p = Success probability per trial.
-
- Key Properties:
- Mean (Expected Value): μ=n×pμ=n×p
- Variance: σ2=n×p×(1−p)σ2=n×p×(1−p)
- Bernoulli Process:
- Named after mathematician Jakob Bernoulli.
- Each trial is independent with outcomes 1 (success) or 0 (failure).
Examples
- Vacation Directions (Yes/No Survey)
Problem:
- You ask 100 strangers for directions, with a 50% chance (p = 0.5) each says « yes. »
- What’s the probability that exactly 66 answer « yes »?
Formula:
BINOM.DIST(66; 100; 0.5; FALSE) // Exact probability
Result: 0.05% (see Figure below).
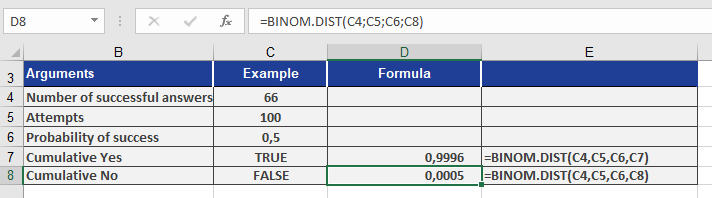
Cumulative Probability (≤66 yes answers):
BINOM.DIST(66, 100, 0.5, TRUE) // Returns ~100%
- Damaged Packages (Quality Control)
Problem:
- A factory produces 2,000 packages, with a 2% defect rate (p = 0.02).
- What’s the probability that exactly 30 are damaged?
Formula:
BINOM.DIST(30; 2000; 0.02; FALSE) // Exact probability
Result: 1.8% (see Figure below).
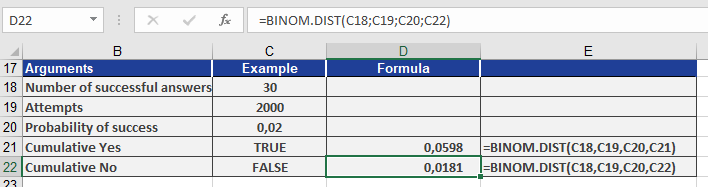
Cumulative Probability (≤30 damaged):
BINOM.DIST(30; 2000; 0.02; TRUE) // Returns 6%
Key Notes
- When to Use:
- FALSE: For exact counts (e.g., « What’s the chance of exactly 3 wins in 5 games? »).
- TRUE: For thresholds (e.g., « What’s the chance of ≤3 wins? »).
- Assumptions:
- Trials must be independent (e.g., survey responses don’t influence each other).
- probability_s must stay constant across trials.
- Limitations:
- For large trials (e.g., >1000), consider approximations like the Poisson or Normal distribution.
How to use the BETA.INV() function in Excel
This function returns the inverse of the beta cumulative distribution. Given a probability, it finds the corresponding value x such that:
- If probability = BETA.DIST(x, …), then BETA.INV(probability, …) = x.
Syntax
BETA.INV(probability; alpha; beta; [A]; [B])
Common Use Case:
- In project planning, it estimates completion times based on expected duration and variance.
Arguments
Argument Required? Description probability Yes A probability (0 ≤ probability ≤ 1) linked to the beta distribution. alpha Yes Shape parameter (must be > 0). beta Yes Shape parameter (must be > 0). A No Lower bound (default = 0). B No Upper bound (default = 1). Note: If A is specified, B must also be provided.
Background
- Beta Distribution Basics:
- Models continuous probabilities for variables bounded in [0, 1].
- Defined by shape parameters alpha (p) and beta (q).
- Probability Density Function :
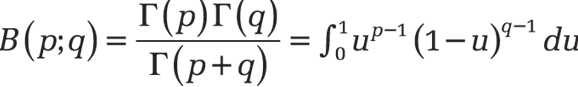
-
-
- B(p, q) = Beta function (normalization factor).
- Γ(p) = Gamma function.
-
- Key Properties:
- Expected Value: E[X] = alpha / (alpha + beta)
- Variance: Var(X) = (alpha * beta) / [(alpha + beta)^2 * (alpha + beta + 1)]
- Inverse Function:
- BETA.INV() reverses BETA.DIST(), returning the quantile x for a given probability.
Example
Problem:
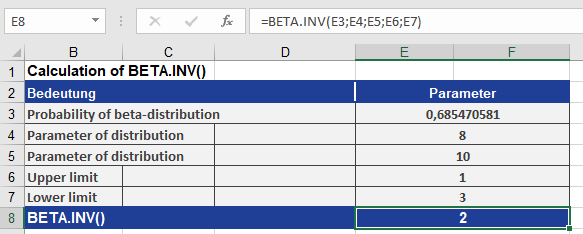
- Given a beta distribution with:
- Shape parameters: alpha = 8, beta = 10
- Bounds: A = 1, B = 3
- What value x corresponds to a cumulative probability of 0.68547?
Formula:
BETA.INV(0.685470581, 8, 10, 1, 3)
Result: 2 (see Figure below).
Interpretation:
- There is a 68.547% probability that a random variable from this distribution falls below 2 (within the range [1, 3]).
Key Notes
- Bounds Adjustment:
- If A and B are provided, the result scales linearly from [0, 1] to [A, B].
- Applications:
- Project Management: Estimating task durations (PERT analysis).
- Statistics: Modeling proportions (e.g., conversion rates, survey responses).
- Error Handling:
- Returns #NUM! if probability ≤ 0 or ≥ 1, or if alpha/beta ≤ 0.
How to use the BETA.DIST() function in Excel
This function returns values of the cumulative beta distribution, which is commonly used to analyze variance across samples (e.g., modeling proportions like daily computer usage time).
Syntax:
BETA.DIST(x; alpha; beta; cumulative; [A]; [B])Arguments:
- x (required): The value (between A and B) to evaluate.
- alpha (required): A shape parameter of the distribution.
- beta (required): A second shape parameter.
- cumulative (required): A logical value (TRUE = cumulative probability; FALSE = probability density).
- A (optional): Lower bound for x (default = 0).
- B (optional): Upper bound for x (default = 1).
Background
- The beta distribution models probabilities for variables bounded within a fixed interval (e.g., 0 to 1).
- alpha and beta control the distribution’s shape (see Figure below).
- If A and B are omitted, x must be between 0 and 1.
Example
Question:
What is the cumulative probability of x = 2 for a beta distribution with:- Shape parameters alpha = 8, beta = 10
- Bounds A = 1, B = 3?
Formula:
BETA.DIST(2, 8, 10, TRUE, 1, 3)Result: 0.68547 (see Figure below).
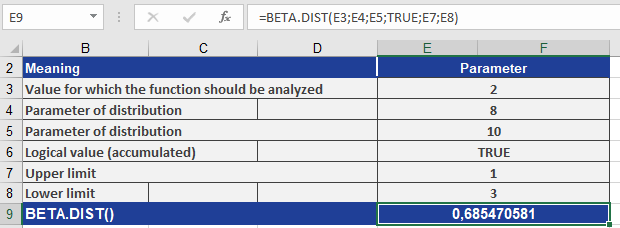
Interpretation:
There is a 68.547% probability that a randomly selected value from this distribution falls between 1 and 2.Key Notes
- Bounds: If A and B are specified, x must lie within [A, B].
- Cumulative vs. Density:
- TRUE: Returns the cumulative distribution (area under the curve up to x).
- FALSE: Returns the probability density at x.
- Applications: Useful for modeling proportions (e.g., task completion rates, survey responses).
How to use the AVERAGEIFS() function in Excel
This function calculates the average of cells that meet multiple specified criteria.
Syntax:
AVERAGEIFS(average_range; criteria_range1; criteria1; [criteria_range2; criteria2]; …)Arguments:
- average_range (required): The range of cells to average (must contain numeric values).
- criteria_range1 (required): The first range to evaluate against criteria1.
- criteria1 (required): The condition applied to criteria_range1 (number, expression, cell reference, or text).
- criteria_range2, criteria2, … (optional): Additional ranges and their associated criteria (up to 127 pairs).
Background
For general details on averages, see the AVERAGE() function description. Like AVERAGEIF(), AVERAGEIFS() measures central tendency but allows for multiple filtering conditions.
Example
Continuing the email marketing analysis from AVERAGEIF():
- You previously calculated the average click rate per mailing type.
- Now, you want to refine the analysis by excluding low click rates (<10,000) to avoid outlier distortion.
Formula Setup:
- average_range: D2:D30 (click rates to average).
- criteria_range1: C2:C30 (mailing types, e.g., « Software A »).
- criteria1: « Software A » (only include this mailing type).
- criteria_range2: D2:D30 (click rates again, for the second filter).
- criteria2: « >10000 » (only include clicks >10,000).
Result:
The average click rate for « Software A » mailings exceeding 10,000 clicks is 15,221.50 (as seen below).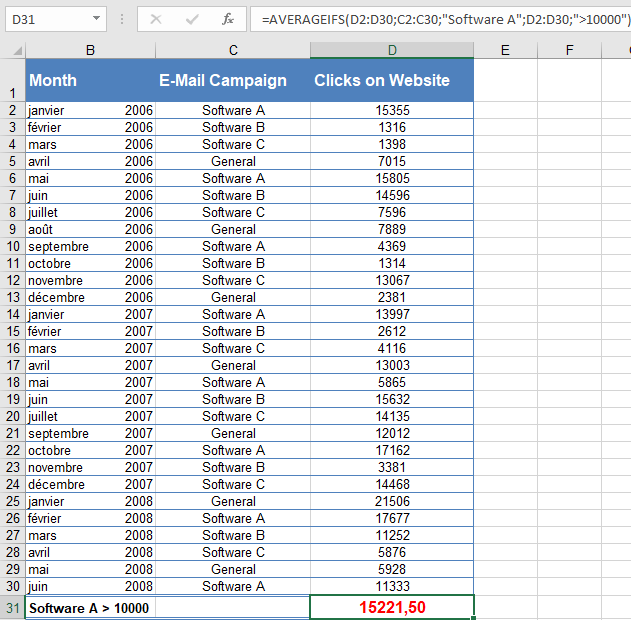
Key Notes
- Order Matters: The first argument is always the range to average, followed by criteria pairs.
- Flexibility: Supports numeric, text, and logical criteria (e.g., « >10000 », « =Completed »).
- Exclusion Logic: Unlike AVERAGEIF(), AVERAGEIFS() requires all criteria to be met for a cell to be included.
How to use the AVERAGEIF() function in Excel
This function calculates the average of all cells in a range that meet a specified criterion.
Syntax:
AVERAGEIF(range; criteria; [average_range])Arguments:
- range (required): The range of cells to evaluate against the criteria. These can include numbers, names, arrays, or references.
- criteria (required): The condition that determines which cells are averaged. It can be a number, expression, cell reference, or text.
- average_range (optional): The actual cells to average. If omitted, the function uses the range argument for both criteria evaluation and averaging.
Background:
For general information on averages, see the description of AVERAGE().The AVERAGEIF() function measures central tendency—the location of the center of a group of numbers in a statistical distribution. Unlike AVERAGE(), it allows you to apply a criterion that filters which values contribute to the mean.
The three most common measures of central tendency are:
- Average (Mean): The arithmetic mean of the distribution.
- Median: The middle value in a sorted list of numbers.
- Mode: The most frequently occurring value in a dataset.
In a symmetrical distribution, these measures are identical. In a skewed distribution, they may differ.
Example:
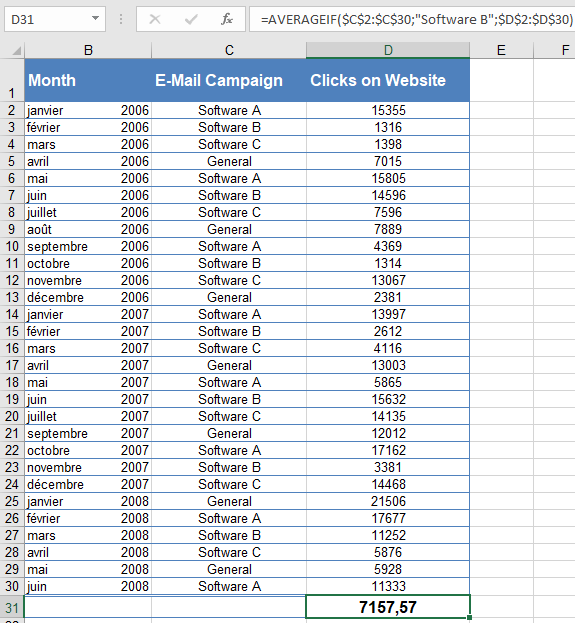
Your software company markets its products through email newsletters. To analyze engagement, you track the click rates on your website after each mailing over the past 30 months.Question: What is the average click rate after « Software B » mailings?
Using AVERAGEIF():
- Range (criteria evaluation): C2:C30 (contains mailing types, e.g., « Software B »).
- Criteria: « Software B » (only cells matching this label are considered).
- Average_range: D2:D30 (contains click rates to average).
Result: The average click rate after « Software B » mailings is 7,157.57 (see Figure below).
How to use the AVERAGEA() function in Excel
This function calculates the average of the values in an argument list. Unlike AVERAGE(), it includes not only numbers but also text and logical values (TRUE and FALSE) in the calculation.
Syntax:
AVERAGEA(value1; [value2] …)Arguments:
- value1(required) and value2 (optional): At least one and up to 255 arguments for which you want to calculate the average.
Background:
For more details on averages, refer to the definition of AVERAGE().The following rules apply to AVERAGEA():
- If an argument contains text (specified as an array or reference), it is evaluated as 0.
- Arguments containing TRUEevaluate as 1, and those containing FALSE evaluate as 0.
Note: If you do not want to include text values in the calculation, use the AVERAGE() function instead.
Example:
You work in the controlling department of a software company and create an Excel table containing sales data for the past twelve months.Since the list includes text and logical values, you calculate the average sales using AVERAGEA().
- In the first column, you enter the text « Closed » for February (see Figure below). Because AVERAGEA()automatically converts text to 0, all 12 values are summed, and the total is divided by 12. The result is $916.67.
- The second column contains TRUEinstead of « Closed. » This logical value is evaluated as 1. Again, all 12 values are summed, and the total is divided by 12. The result is $916.75.
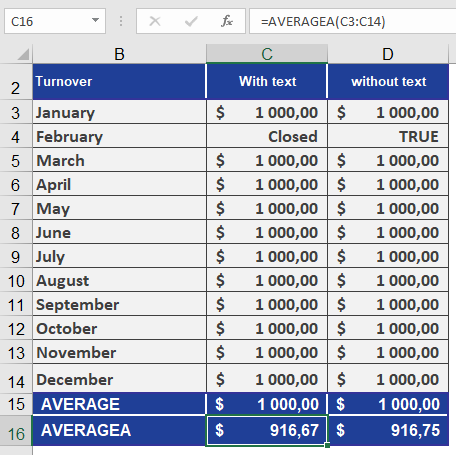
If you had used AVERAGE() instead, text values would be excluded—only 11 values would be summed, and the total divided by 11. In this case, the result would be $1,000.00.
How to use the AVERAGE() function in Excel
This function returns the average (arithmetic mean) of the arguments. To calculate the average, interval-scaled variables are summed and then divided by their count.
Syntax
AVERAGE(number1, number2, …)
Arguments
- number1 (required) and number2 (optional): At least one and up to 255 arguments (30 in Excel 2003 and earlier versions) for which you want to calculate the average.
Background
The arithmetic mean is the most well-known measure of central tendency and is widely used, even among non-statisticians. Because it incorporates all values in its calculation, it plays a key role in inferential statistics.
To compute the mean:
- Sum all values in a range.
- Divide the total by the number of values.
The arithmetic mean requires interval-scale data.
The combined mean of two datasets can also be derived from their individual arithmetic means.
Limitations
- Sensitivity to outliers: Extreme values significantly affect the mean since all data points are included.
- Potential misrepresentation: The mean may not align with actual observed values, especially in skewed distributions.
- Grouped data: For grouped or continuous variables, the arithmetic mean is only an estimate unless additional information about central tendency is available.
Applicability to Ordinal Data
Although the arithmetic mean typically requires metric-scale data, it can sometimes be applied to ordinal-scale data (e.g., customer satisfaction surveys) under certain conditions:
- The sample size is sufficiently large (n > 30).
- Data distribution approximates normality.
- A confidence interval is provided for the mean.
Comparison with Other Measures of Central Tendency
For datasets allowing arithmetic mean calculation, the mode and median can also be determined. The best measure depends on the context:
- Mean: Uses all data points but is sensitive to outliers.
- Median: Robust against outliers, ideal for skewed distributions.
- Mode: Best for categorical or highly clustered data.
Example
As a marketing manager for a software company, you need to calculate the average webpage visits in 2024 to identify high- and low-traffic areas.
Steps:
- Import website visit data into Excel.
- Use a PivotTable to organize visits by section (Products, Publications, Team, Training, Knowledge).
- Apply the AVERAGE() function to determine the mean visits per area.
Findings (see Figure below):
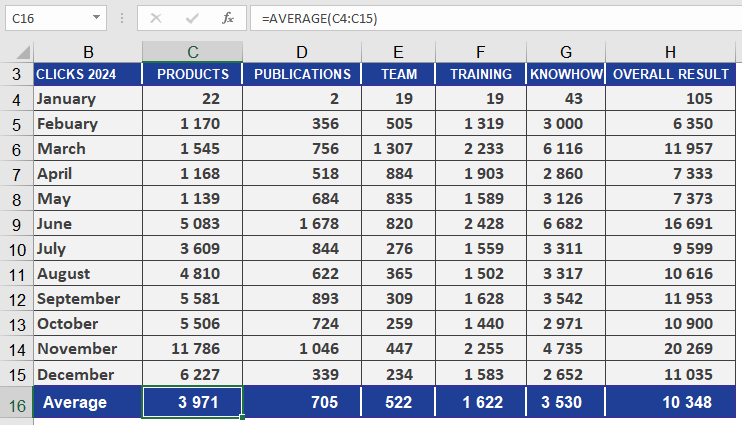
- The Products section has significantly more visits than Publications.
- The yearly average across all sections provides an overview of overall website activity.
- Comparing results with prior years enables trend analysis.
How to use the AVEDEV() function in Excel
This function returns the average of the absolute deviations of data points from their mean. The function calculates the arithmetic mean of the deviations of a data set based on the average, excluding the sign.
Syntax:
AVEDEV(number1, number2, …)AVEDEV() is a measure of the variance in a data set.
Arguments:
- number1(required) and number2 (optional): At least one and up to 255 arguments for which you want to calculate the absolute deviation. You can also use a single array or a reference to an array instead of arguments separated by commas.
Background:
To calculate the deviation of sales or, as in our example, the monthly website visits relative to the mean, use the AVEDEV() function.AVEDEV() is a measure of the variance in a data set.
In a sense, measures of dispersion serve as a quality criterion for the measure of central tendency. These measures indicate the accuracy of a measure of central tendency. Variance parameters refer to the difference between the following:
- Location values (range, quartile, or semi-quartile distance)
- Individual values and a mean (average linear deviation, variance, standard deviation)
Example:
The marketing department of a software company wants to analyse customer website visits. The visits to various website areas over the past 18 months are recorded in an Excel table (see table below).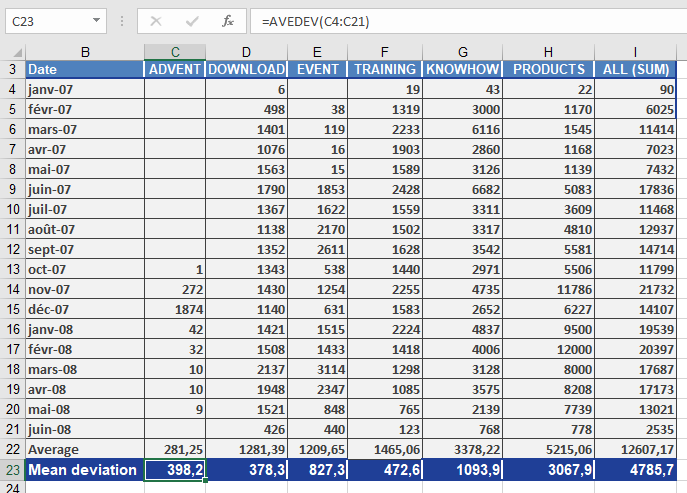
Since the average deviation refers to the mean values in the data sets, the marketing department calculates the mean value for each website area using the AVERAGE() function. Afterwards, they calculate the average deviation for each data set. The AVEDEV() function returns the results—the arithmetic mean of the deviation from the mean value.
Now, the mean values and average deviations can be compared and analyzed. The following conclusions can be drawn from this result:
The AVEDEV() function is a measure of the variance in a data set, where the variance parameters refer to the differences between individual values and mean values.
For example, the average deviation for the DOWNLOAD area is 378.3 per month. This means that, compared to the calculated mean value, the visits to the DOWNLOAD area vary by 378.3 each month.
How to use the CUBEVALUE function in Excel
This function returns the value of a member (cell) from a cube.
Syntax
CUBEVALUE(connection; member_expression1; member_expression2; …)
Arguments
- connection (required): A string representing the name of the workbook connection to the cube, enclosed in quotation marks. After you type the first quotation mark, existing context-sensitive data connections will be displayed.
- member_expression1 (required) and member_expression2 (optional): You must provide at least one and up to 255 expressions that define the position of a member in the cube based on a Multidimensional Expression (MDX). The expression can be entered directly or referenced from a cell. Tuples can also be used in expressions. Alternatively, a member_expression can be a set defined with the CUBESET() function. If no measure is specified in a member_expression, the default measure for that cube is used. Because this argument can be repeated, you can define intersections. You can also use tuples.
Background
When you use CUBEVALUE() as an argument for another cube function, the MDX expression (rather than the displayed value) is used in the argument.
Error values and messages provide information about incorrect or missing entries:
- If the connection name is not a valid workbook connection, the CUBEVALUE() function returns the #NAME? error.
- If the OLAP server (or the offline cube) is unavailable, an error message will appear, but the content of the affected cell will not change.
- If at least one member within the arguments or the tuple is invalid, the CUBEVALUE() function returns the #VALUE!.
- If a member_expression is longer than 255 characters, the CUBEVALUE() function returns the #VALUE!.
- CUBEVALUE() returns the #N/A error when:
- The member_expression syntax is incorrect.
- The member specified in the MDX query does not exist in the cube.
- The tuple is invalid because there is no intersection for the specified values.
- The set contains at least one member with a different dimension from the other members.
- CUBEVALUE() might also return the #N/A error when the connection to the data source is interrupted and cannot be re-established.
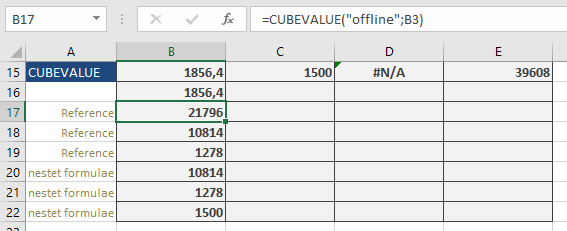
The formula: =CUBEVALUE(« offLine », »[Measures].[GrossSales] », »[Stores].[Store].[All].[NorthEast] », »[Years].[Year].[All].[2009] », »[Products].[Product].[All].[Cookies] ») calculates the gross sales for cookies in the « NorthEast » store in the year 2009, which is $1,856.40. You will get the same result if you use a tuple (where the arguments of the previous formula are enclosed in parentheses): =CUBEVALUE(« offline », »([Measures].[GrossSales],[Stores].[Store].[All].[NorthEast],[Years].[Year].[All].[2009],[Products].[Product].[All].[Cookies]) »)
If you enter the formula =CUBEMEMBER(« offLine », »[Products].[Product].[All].[Cookies] ») in cell B3, then the formula =CUBEVALUE(« offline »,B3) returns the total sales for cookies: $21,796.
You can also use examples from the CUBEKPIMEMBER() function. For instance, the formula: =CUBEVALUE(« offline »,CUBERANKEDMEMBER(« offline »,CUBESET(« offline », »[Stores].[Store].Children », »all store sales »,2; »[Measures].[Sale] »),1)) returns $10,814 for the total sales of the best-performing store (« NorthEast »).